PostgreSQL刪除一堆欄位資料,資料庫佔用硬碟空間反而變大
一個原本佔用磁碟空間25.921GB的資料庫,刪除某個欄位內容資料(SET foo=''),大概1000萬筆資料,發現資料庫佔用空間反而變大: 33.478GB(花了1703秒)。
PostgreSQL有個VACUUM指令,試用看看,果然執行完磁碟空間變成24.8GB(花了1106秒)。
VACUUM FULL清的最乾淨,但是花時間,而且會lock table,正式站要小心使用。
一個原本佔用磁碟空間25.921GB的資料庫,刪除某個欄位內容資料(SET foo=''),大概1000萬筆資料,發現資料庫佔用空間反而變大: 33.478GB(花了1703秒)。
PostgreSQL有個VACUUM指令,試用看看,果然執行完磁碟空間變成24.8GB(花了1106秒)。
VACUUM FULL清的最乾淨,但是花時間,而且會lock table,正式站要小心使用。
Pillow (PIL Fork) 10.4.0 documentation
Usage:
thumb = Image.open(img)
thumb.thumbnail(i[1] , Image.LANCZOS)
# thumb = thumb.convert('RGB')
thumb.save(target_path, "JPEG")
thumb.close()
演算法可以參考下圖。
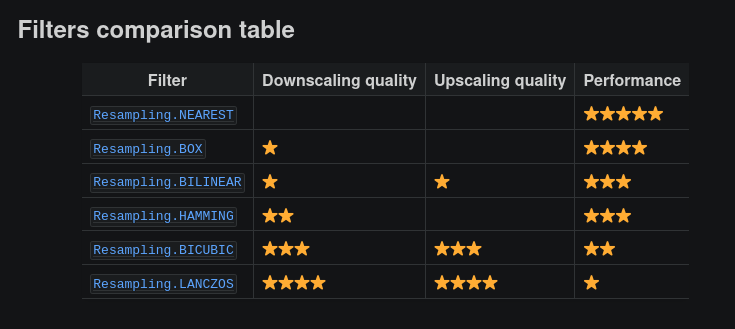
screenshot via: Filters
Uploadcare提供了SIMD加速的Pillow: uploadcare/pillow-simd: The friendly PIL fork
Benchmark測試 Pillow Performance
CPU: Intel Celeron N4505 2.0GHz
安裝libjpeg-dev, zlib1g-dev後,安裝pillow-simd才會成功。但執行python出現illegal hardware instruction的錯誤訊息。
# install requirements
sudo apt install libjpeg-dev zlib1g-dev
# install pillow-simd
CC="cc -mavx2" pip install -U --force-reinstall pillow-simd
MacBook Pro: 3.1GHz Intel Core i7
用brew安裝jpeg後,安裝pillow-simd成功,執行也沒問題。
速度有比較快,希望有空來做benchmark。
隨筆紀錄一下TDWG 2020關於自然史典藏系統的討論(線上),已經是4年前的討論了,有的似乎也沒有在維護了,仍有參考價值。
Vince Smith
英國自然史提出的解決方案,完整的data model,滿強調Linked Data,很有啟發性。
多人協作?
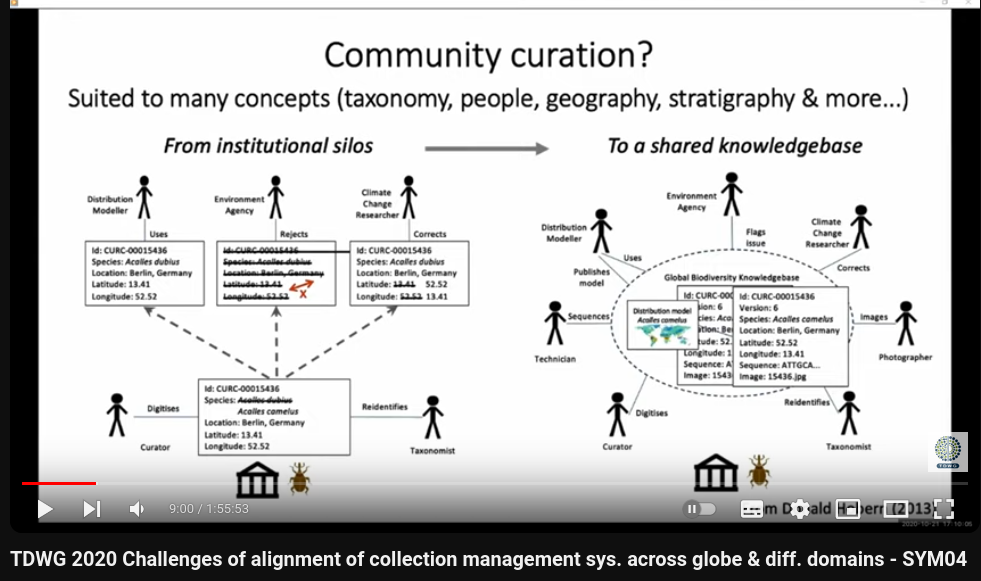
NHM data workflow
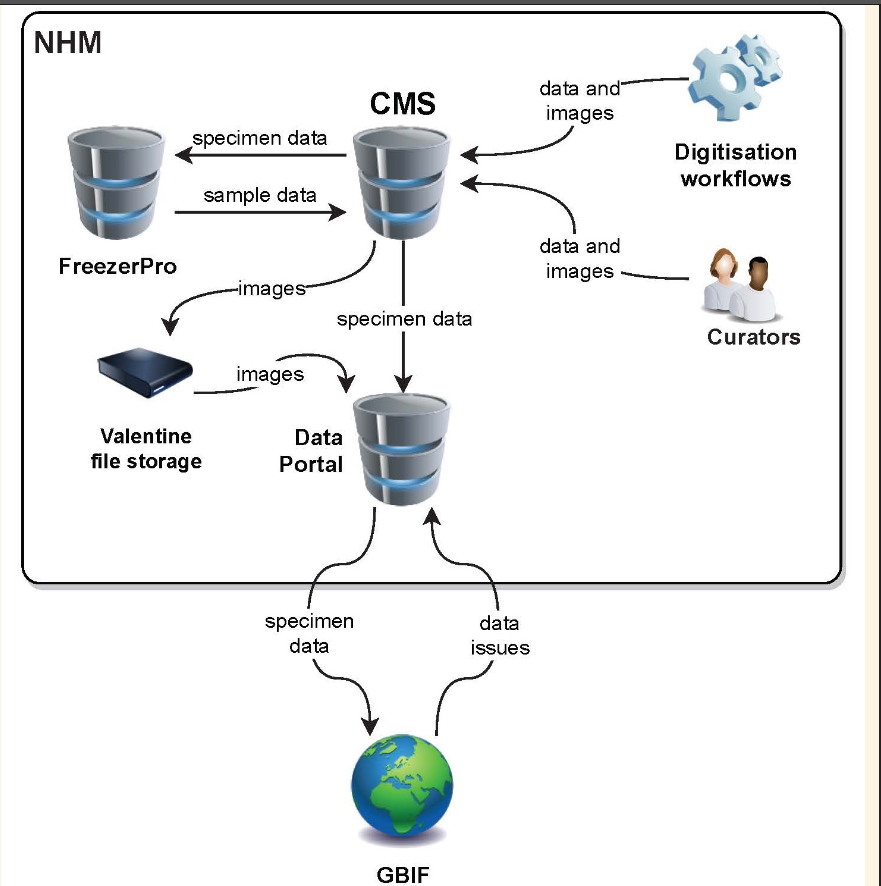
NHM與世界的連結

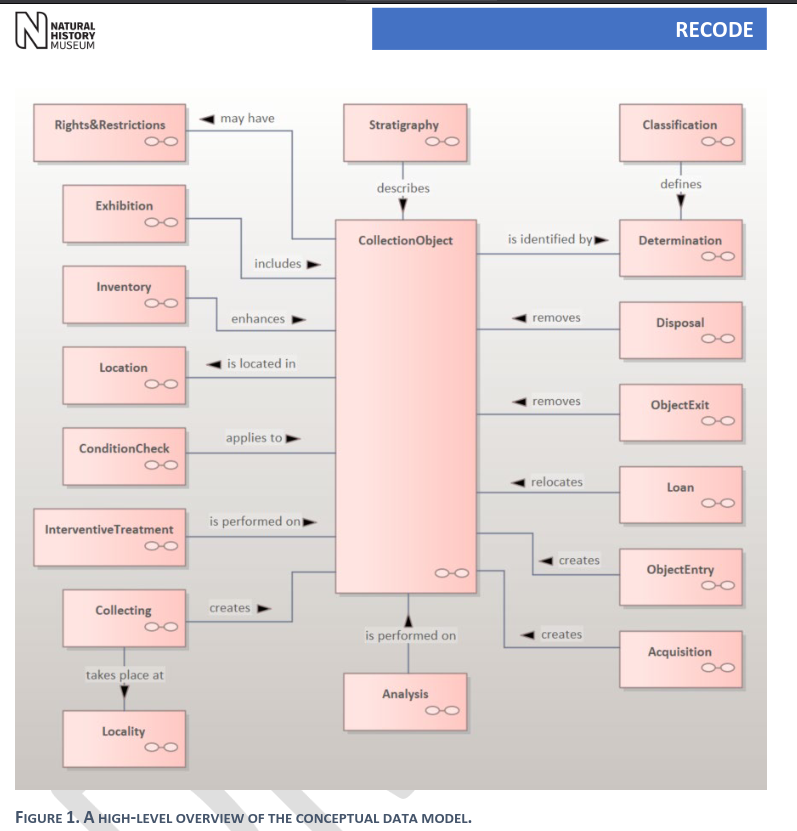
RECODE Data Model的關鍵: CollectionObject
芬蘭的自然史典藏系統,強調Simple and Flexible,不用關聯式資料庫,很像新創邊移動邊開槍的模式。
Mikko Heikkinen
Collection Management System | Suomen Lajitietokeskus
沒有好用的系統、又有開發的人,所以就可以自幹

跨組織要使用,要讓系統簡單而保持彈性。因為非技術的問題就夠麻煩的了。

去中心化系統很厲害,但感覺要花很多精力處理系統之間的同步,不知道是不是美國這種人多地大物博的才運作的起來?
Edward Gilbert
新版(Specify 7)轉移到網頁,很大的破壞式更新。
不知道是不是沒繼續了,感覺沒有很活躍?
DIgital Information system for NAtural history data)
很讚的總結,但我暫時無法吸收了。
Matt Yoder
| Name | start | mantance | status | tech stack | stats |
|---|---|---|---|---|---|
| RECODE | 2022 | NHM | good model concept | ||
| Kotka | 2012 | Finnish Museum of Natural History Luomus | PHP, Zend | 2020: 2.5 million specimens,12 institutions | |
| Symbiota | 2008 | Arizona State University | PHP | 2020:50-60 public portals | |
| Specify | Specify Collections Consortium | ||||
| DINA | 2014 | RBGE? | not available (2024) | web |
Smashing Newsletter 看到關於大眾運輸的Design System,有趣。
Select dataset:
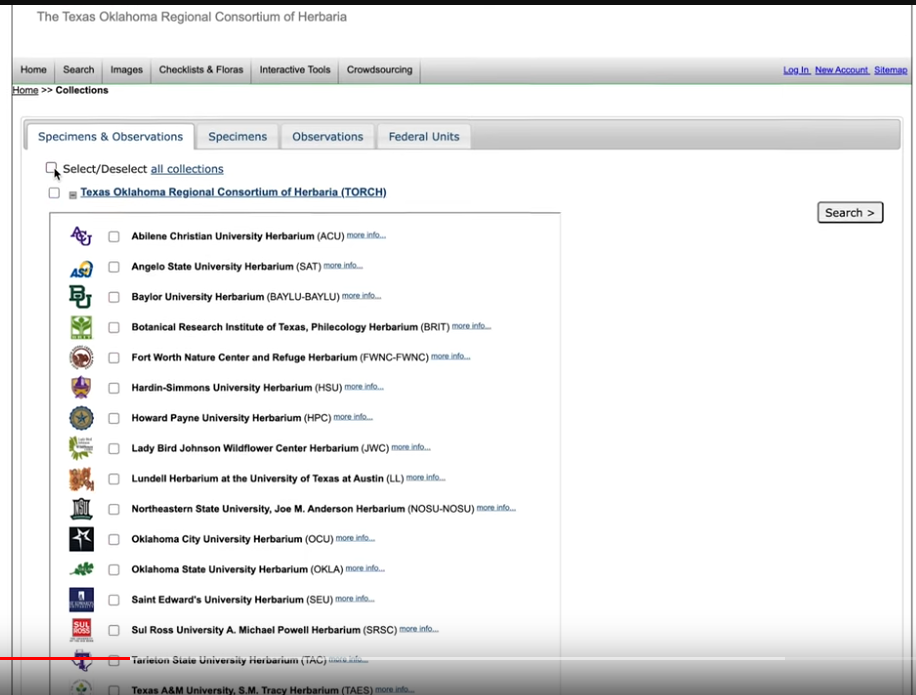
Filter by taxon:
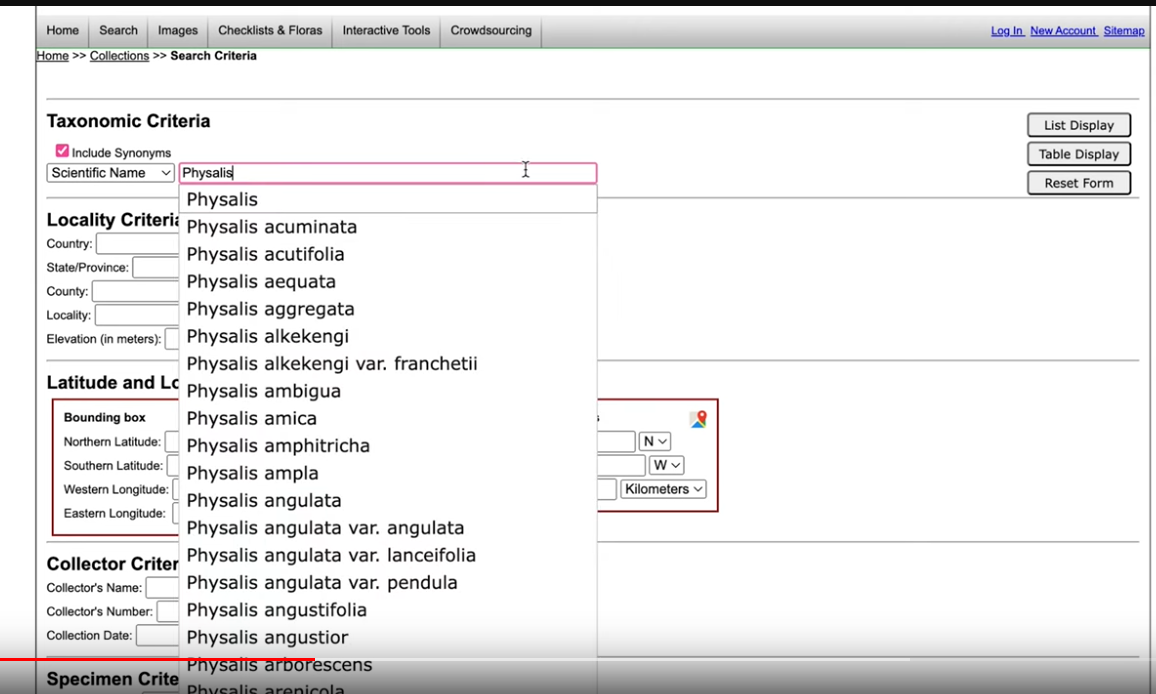
Other Filters:
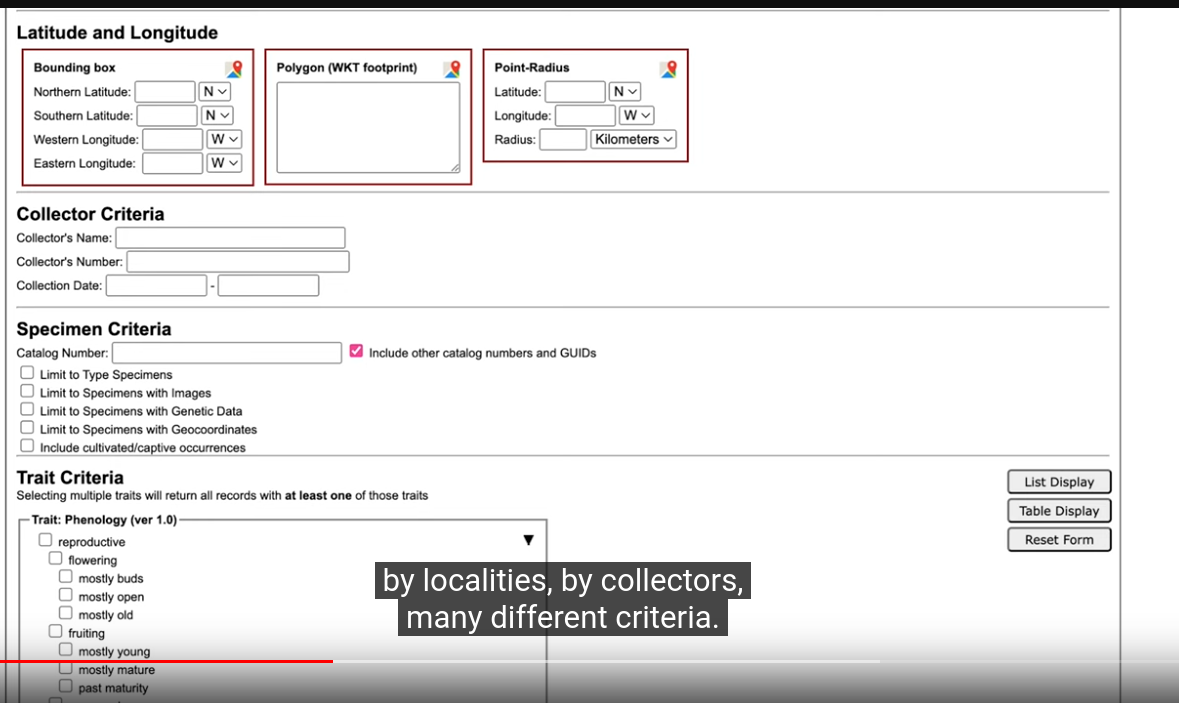
Filter results:
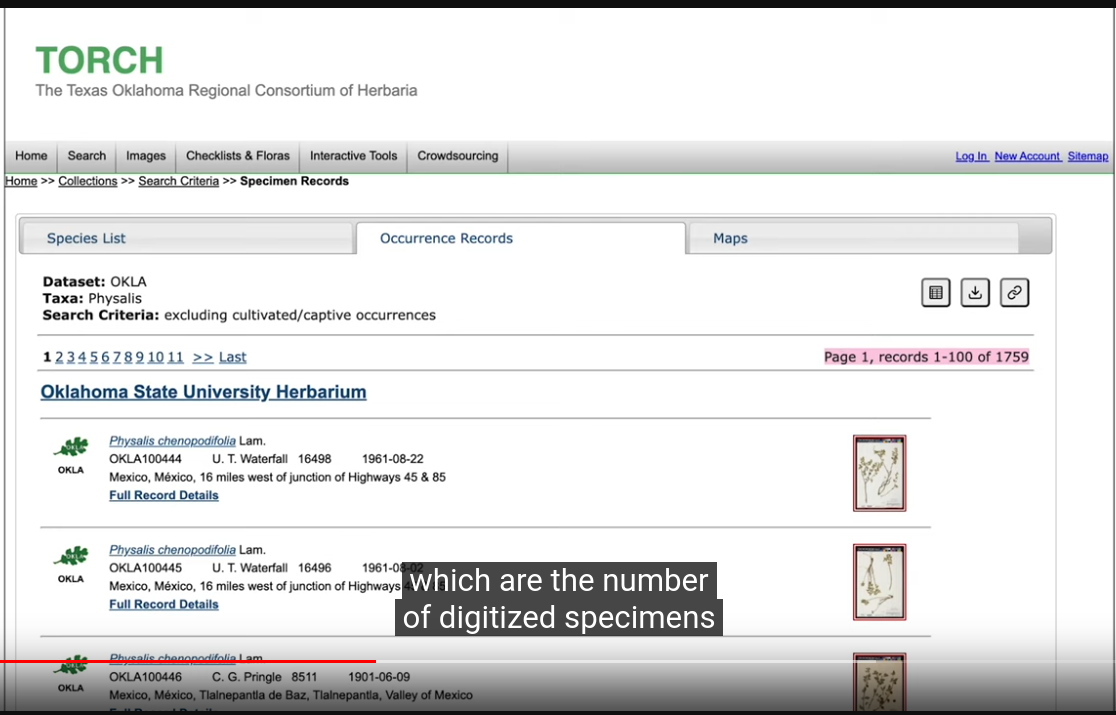
Species page:
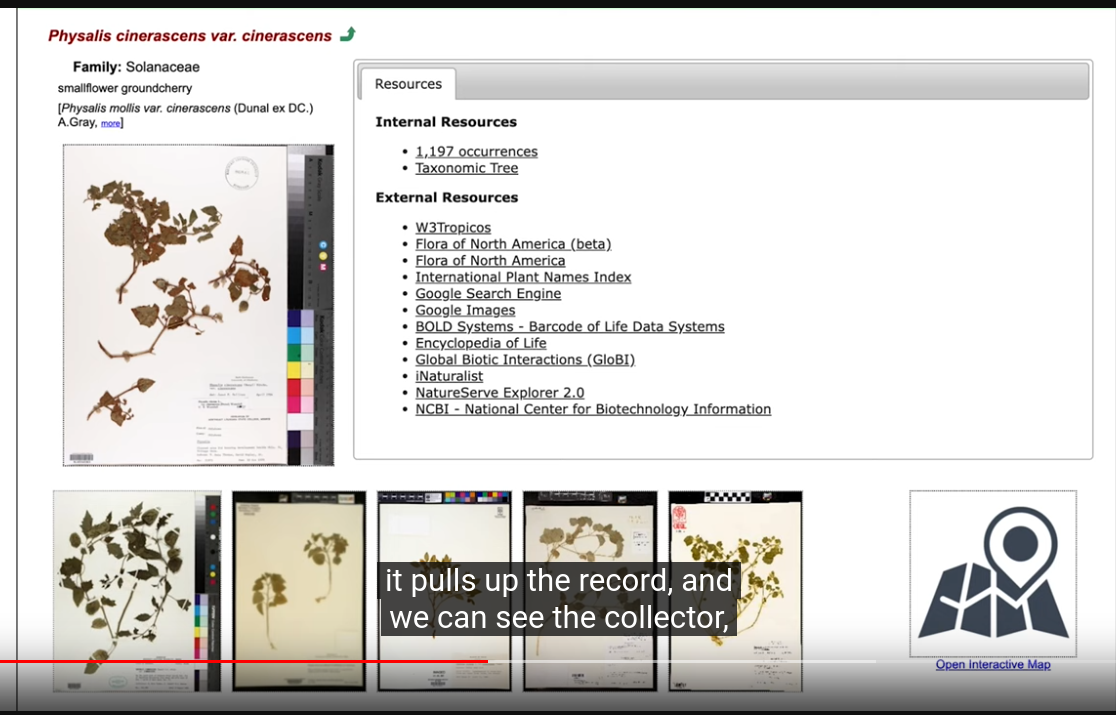
Specimen page:

Imaging:

Transcription from label and image information by volunteering and student worker
upload images to Notes from Nature — Zooniverse for volunteers to help transcribe.
ref: Digitizing Herbariums for Future Historians - YouTube
start: 2023年4月 2024-05-30
https://www.youtube.com/watch?v=fegAeph9UaA&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49
Deep Learning Specialization [5 courses] (DeepLearning.AI) | Coursera
Drafting and Crafting a “System” Together with Generative AI
Sunny, STR Network
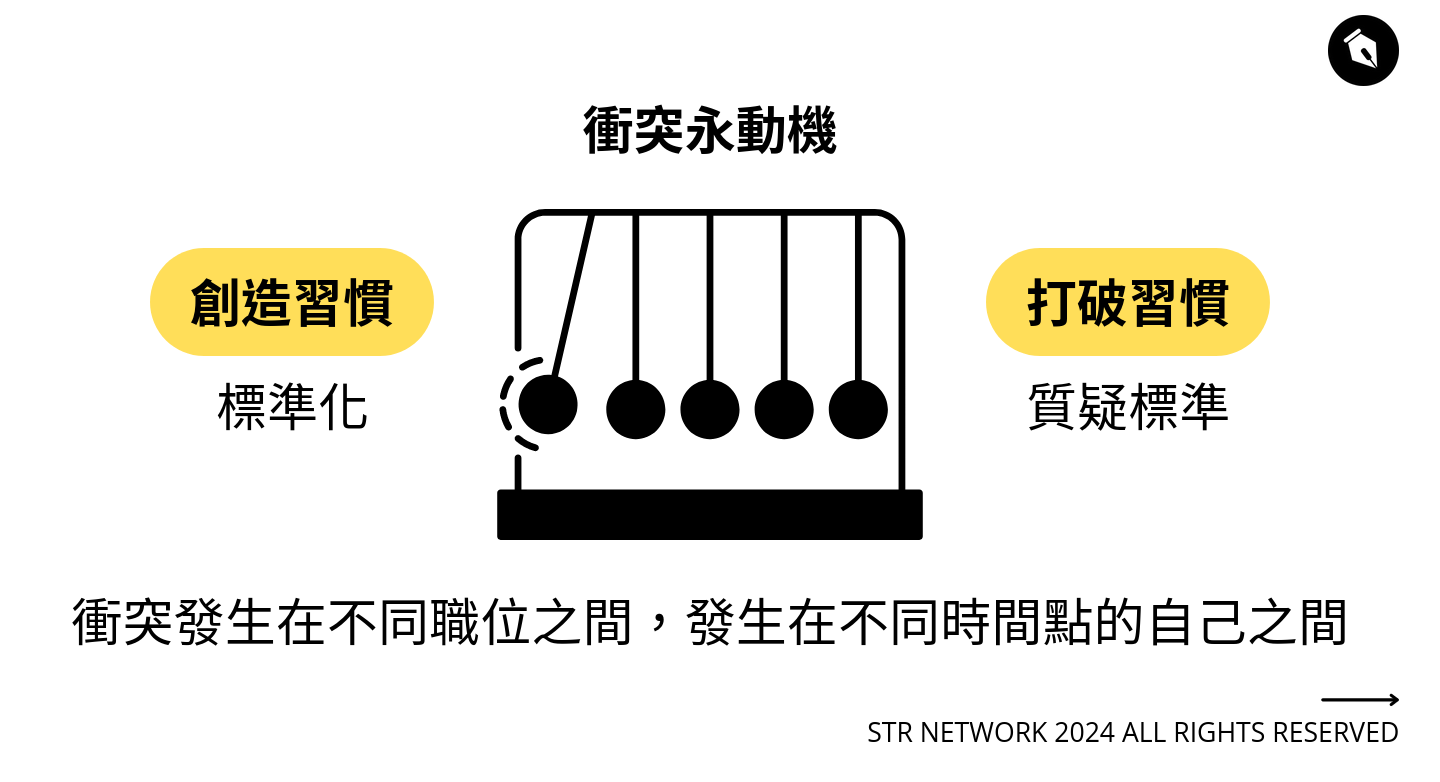
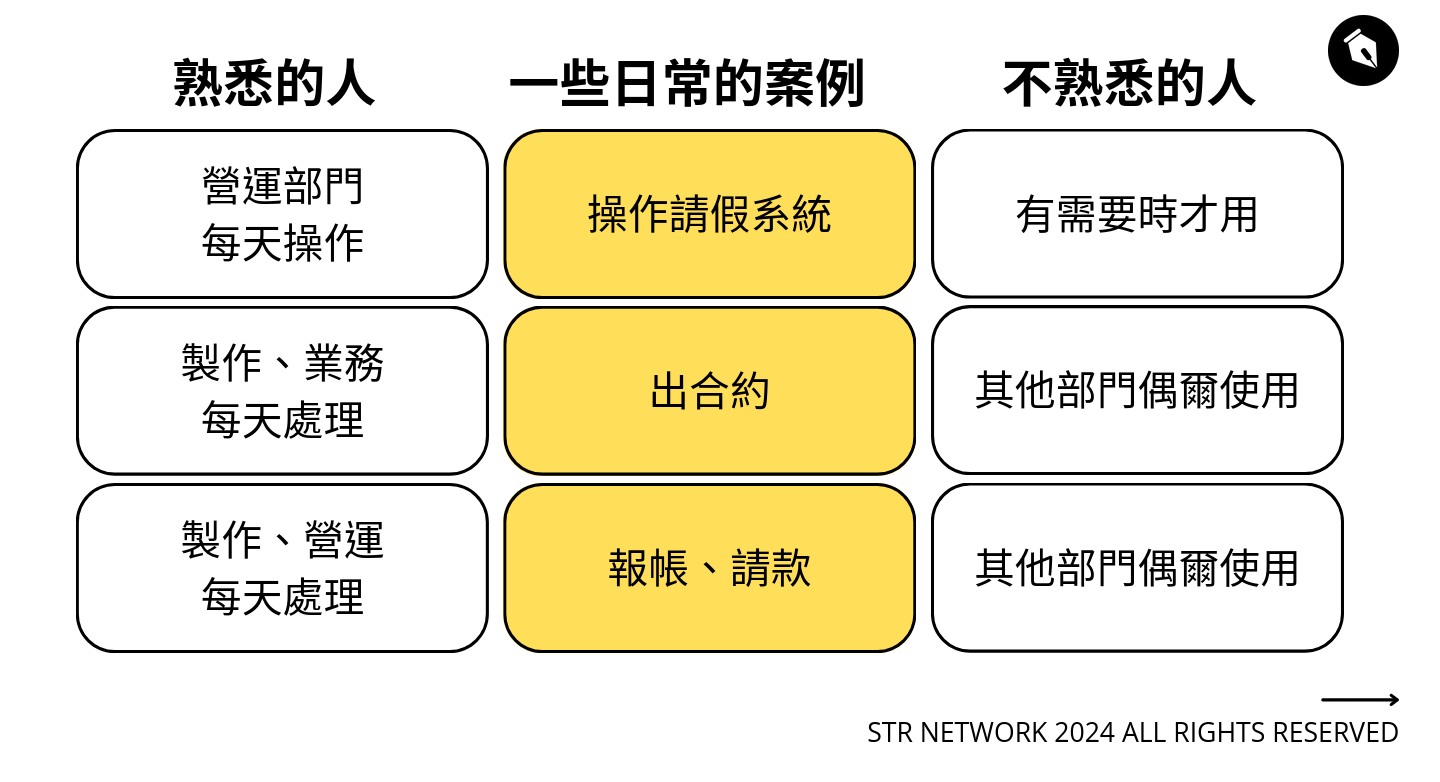
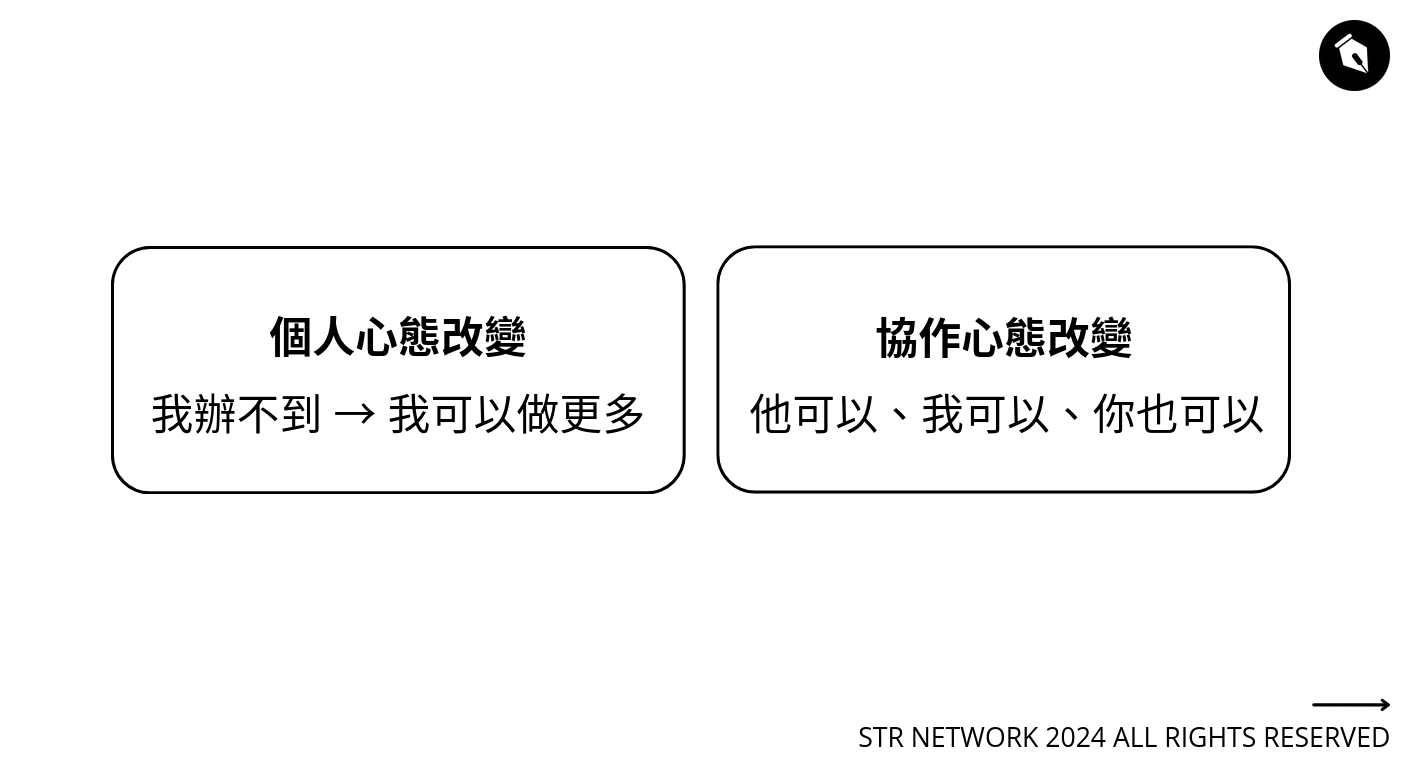
很有啟發,重點不是技術,而是建立系統的過程跟思考。





https://mammals3.exhibit.jp/ (失效25.01.14)